Apache Kafka est une plateforme de streaming distribuée. Il est utile pour créer des pipelines de données de diffusion en temps réel afin d'obtenir des données entre les systèmes ou les applications. Une autre fonctionnalité utile est les applications de streaming en temps réel qui peuvent transformer des flux de données ou réagir sur un flux de données.
Ce tutoriel vous aidera à installer Apache Kafka sur les systèmes Debian 10, Debian 9 et Debian 8.
Étape 1 – Installer Java
Apache Kafka avait besoin de Java pour s'exécuter. Vous devez avoir java installé sur votre système. Exécutez la commande ci-dessous pour installer OpenJDK par défaut sur votre système à partir des PPA officiels.
sudo apt update sudo apt install default-jdk
Étape 2 – Télécharger Apache Kafka
Téléchargez les fichiers binaires Apache Kafka à partir de son site Web de téléchargement officiel. Vous pouvez également sélectionner n'importe quel miroir à proximité pour le télécharger.
wget http://www-us.apache.org/dist/kafka/2.7.0/kafka_2.13-2.7.0.tgz
Ensuite, extrayez le fichier d'archive
tar xzf kafka_2.13-2.7.0.tgz mv kafka_2.13-2.7.0 /usr/local/kafka
Étape 3 - Créer des fichiers d'unité Systemd
Ensuite, créez des fichiers d'unité systemd pour le service Zookeeper et Kafka. Cela aidera à gérer les services Kafka pour démarrer/arrêter à l'aide de la commande systemctl.
Tout d'abord, créez un fichier d'unité systemd pour Zookeeper avec la commande ci-dessous :
vim /etc/systemd/system/zookeeper.service
Ajoutez le contenu ci-dessous :
[Unit] Description=Apache Zookeeper server Documentation=http://zookeeper.apache.org Requires=network.target remote-fs.target After=network.target remote-fs.target [Service] Type=simple ExecStart=/usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties ExecStop=/usr/local/kafka/bin/zookeeper-server-stop.sh Restart=on-abnormal [Install] WantedBy=multi-user.target
Enregistrez le fichier et fermez-le.
Ensuite, pour créer un fichier d'unité Kafka systemd à l'aide de la commande suivante :
vim /etc/systemd/system/kafka.service
Ajoutez le contenu ci-dessous. Assurez-vous de définir le bon JAVA_HOME chemin selon Java installé sur votre système.
[Unit] Description=Apache Kafka Server Documentation=http://kafka.apache.org/documentation.html Requires=zookeeper.service [Service] Type=simple Environment="JAVA_HOME=/usr/lib/jvm/java-1.11.0-openjdk-amd64" ExecStart=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh [Install] WantedBy=multi-user.target
Enregistrez le fichier et fermez.
Rechargez le démon systemd pour appliquer les nouvelles modifications.
systemctl daemon-reload
Étape 4 - Démarrer le serveur Kafka
Kafka a requis ZooKeeper, donc commencez par démarrer un serveur ZooKeeper sur votre système. Vous pouvez utiliser le script disponible avec Kafka pour démarrer une instance ZooKeeper à nœud unique.
sudo systemctl start zookeeper
Démarrez maintenant le serveur Kafka et affichez l'état d'exécution :
sudo systemctl start kafka sudo systemctl status kafka
Terminé. L'installation de Kafka s'est terminée avec succès. La partie de ce tutoriel vous aidera à travailler avec le serveur Kafka.
Étape 5 – Créer un sujet dans Kafka
Kafka fournit plusieurs scripts shell pré-construits pour travailler dessus. Tout d'abord, créez un sujet nommé "testTopic" avec une seule partition avec un seul réplica :
cd /usr/local/kafka bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTopic Created topic testTopic.
Le facteur de réplication décrit le nombre de copies de données qui seront créées. Comme nous fonctionnons avec une seule instance, gardez cette valeur 1.
Définissez les options de partitions en fonction du nombre de courtiers entre lesquels vous souhaitez que vos données soient réparties. Comme nous fonctionnons avec un seul courtier, gardez cette valeur 1.
Vous pouvez créer plusieurs sujets en exécutant la même commande que ci-dessus. Après cela, vous pouvez voir les sujets créés sur Kafka en exécutant la commande ci-dessous :
bin/kafka-topics.sh --list --zookeeper localhost:2181 testTopic TecAdminTutorial1 TecAdminTutorial2
Alternativement, au lieu de créer manuellement des sujets, vous pouvez également configurer vos courtiers pour qu'ils créent automatiquement des sujets lorsqu'un sujet inexistant est publié.
Étape 6 - Envoyer des messages à Kafka
Le « producteur » est le processus chargé de mettre les données dans notre Kafka. Le Kafka est livré avec un client de ligne de commande qui prendra l'entrée d'un fichier ou d'une entrée standard et l'enverra sous forme de messages au cluster Kafka. Le Kafka par défaut envoie chaque ligne dans un message séparé.
Lançons le producteur, puis tapons quelques messages dans la console à envoyer au serveur.
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testTopic >Welcome to kafka >This is my first topic >
Vous pouvez quitter cette commande ou laisser ce terminal en cours d'exécution pour des tests supplémentaires. Ouvrez maintenant un nouveau terminal pour le processus client Kafka à l'étape suivante.
Étape 7 - Utiliser Kafka Consumer
Kafka dispose également d'un consommateur de ligne de commande pour lire les données du cluster Kafka et afficher les messages sur la sortie standard.
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --from-beginning Welcome to kafka This is my first topic
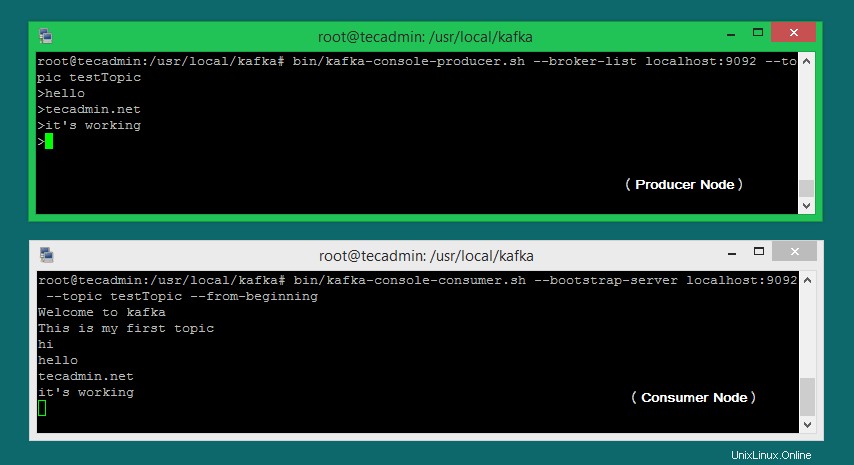
Maintenant, si vous exécutez toujours le producteur Kafka (étape 6) dans un autre terminal. Tapez simplement du texte sur ce terminal de producteur. il sera immédiatement visible sur le terminal du consommateur. Voir la capture d'écran ci-dessous du producteur et du consommateur de Kafka en fonctionnement :
Conclusion
Vous avez installé et configuré avec succès le service Kafka sur la machine Linux Debian.