Cet article examine le montage namespace et est le troisième de la série Linux Namespace. Dans le premier article, j'ai donné une introduction aux sept espaces de noms les plus couramment utilisés, jetant les bases du travail pratique commencé dans l'article sur les espaces de noms d'utilisateurs. Mon objectif est d'acquérir des connaissances fondamentales sur le fonctionnement des fondements des conteneurs Linux. Si vous êtes intéressé par la façon dont Linux contrôle les ressources sur un système, consultez la série CGroup, j'ai écrit plus tôt. J'espère qu'au moment où vous aurez terminé le travail pratique sur les espaces de noms, je pourrai lier les CGroups et les espaces de noms de manière significative, complétant ainsi le tableau pour vous.
Pour l'instant, cependant, cet article examine l'espace de noms de montage et comment il peut vous aider à mieux comprendre l'isolement que les conteneurs Linux apportent aux administrateurs système et, par extension, aux plates-formes comme OpenShift et Kubernetes.
[ Vous pourriez également aimer : Partager des groupes supplémentaires avec des conteneurs Podman ]
L'espace de noms de montage
L'espace de noms de montage ne se comporte pas comme prévu après la création d'un nouvel espace de noms d'utilisateur. Par défaut, si vous deviez créer un nouvel espace de noms de montage avec unshare -m , votre vision du système resterait en grande partie inchangée et non limitée. En effet, chaque fois que vous créez un nouvel espace de noms de montage, une copie des points de montage de l'espace de noms parent est créé dans le nouvel espace de noms de montage. Cela signifie que toute action entreprise sur des fichiers à l'intérieur d'un espace de noms de montage mal configuré sera impact sur l'hôte.
Quelques étapes de configuration pour les espaces de noms de montage
Alors, à quoi sert l'espace de noms de montage ? Pour illustrer cela, j'utilise une archive tar Linux Alpine.
En résumé, téléchargez-le, décompressez-le et déplacez-le dans un nouveau répertoire, en accordant au répertoire de niveau supérieur les autorisations pour un utilisateur non privilégié :
[root@localhost ~] export CONTAINER_ROOT_FOLDER=/container_practice
[root@localhost ~] mkdir -p ${CONTAINER_ROOT_FOLDER}/fakeroot
[root@localhost ~] cd ${CONTAINER_ROOT_FOLDER}
[root@localhost ~] wget https://dl-cdn.alpinelinux.org/alpine/v3.13/releases/x86_64/alpine-minirootfs-3.13.1-x86_64.tar.gz
[root@localhost ~] tar xvf alpine-minirootfs-3.13.1-x86_64.tar.gz -C fakeroot
[root@localhost ~] chown container-user. -R ${CONTAINER_ROOT_FOLDER}/fakeroot
La fakeroot le répertoire doit appartenir à l'utilisateur container-user car une fois que vous avez créé un nouvel espace de noms d'utilisateur, la racine l'utilisateur dans le nouvel espace de noms sera mappé sur le container-user en dehors de l'espace de noms. Cela signifie qu'un processus à l'intérieur du nouvel espace de noms pensera qu'il a les capacités requises pour modifier ses fichiers. Néanmoins, les autorisations du système de fichiers de l'hôte empêcheront l'utilisateur du conteneur compte de modifier les fichiers Alpine à partir de l'archive tar (qui ont racine en tant que propriétaire).
Que se passe-t-il si vous démarrez simplement un nouvel espace de noms de montage ?
PS1='\u@new-mnt$ ' unshare -Umr Maintenant que vous êtes à l'intérieur du nouvel espace de noms, vous ne vous attendez peut-être pas à voir les points de montage d'origine de l'hôte. Cependant, ce n'est pas le cas :
root@new-mnt$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/cs-root 36G 5.2G 31G 15% /
tmpfs 737M 0 737M 0% /sys/fs/cgroup
devtmpfs 720M 0 720M 0% /dev
tmpfs 737M 0 737M 0% /dev/shm
tmpfs 737M 8.6M 728M 2% /run
tmpfs 148M 0 148M 0% /run/user/0
/dev/vda1 976M 197M 713M 22% /boot
root@new-mnt$ ls /
bin container_practice etc lib media opt root sbin sys usr
boot dev home lib64 mnt proc run srv tmp var
La raison en est que systemd partage par défaut les points de montage de manière récursive avec tous les nouveaux espaces de noms. Si vous avez monté un tmpfs système de fichiers quelque part, par exemple, /mnt à l'intérieur du nouvel espace de noms de montage, l'hôte peut-il le voir ?
root@new-mnt$ mount -t tmpfs tmpfs /mnt
root@new-mnt$ findmnt |grep mnt
└─/mnt tmpfs tmpfs rw,relatime,seclabel,uid=1000,gid=1000 L'hôte, cependant, ne voit pas ceci :
[root@localhost ~]# findmnt |grep mnt Donc, à tout le moins, vous savez que l'espace de noms de montage fonctionne correctement. C'est le bon moment pour faire un petit détour pour discuter de la propagation des points de montage. Je résume brièvement, mais si vous êtes intéressé par une meilleure compréhension, consultez l'article LWN de Michael Kerrisk ainsi que la page de manuel de l'espace de noms de montage. Normalement, je ne compte pas autant sur les pages de manuel car je trouve souvent qu'elles ne sont pas faciles à digérer. Cependant, dans ce cas, ils sont pleins d'exemples et en anglais (principalement) simple.
Théorie des points de montage
Les montages se propagent par défaut en raison d'une fonctionnalité du noyau appelée sous-arborescence partagée . Cela permet à chaque point de montage d'avoir son propre type de propagation qui lui est associé. Ces métadonnées déterminent si les nouveaux montages sous un chemin donné sont propagés vers d'autres points de montage. L'exemple donné dans la page de manuel est celui d'un disque optique. Si votre disque optique est automatiquement monté sous /cdrom , le contenu ne serait visible dans d'autres espaces de noms que si le type de propagation approprié est défini.
Groupes d'homologues et états de montage
La documentation du noyau indique qu'un "groupe de pairs est défini comme un groupe de vfsmounts qui propagent des événements les uns aux autres. " Les événements sont des choses telles que le montage d'un partage réseau ou le démontage d'un périphérique optique. Pourquoi est-ce important, demandez-vous ? Eh bien, en ce qui concerne l'espace de noms de montage, les groupes de pairs sont souvent le facteur décisif pour savoir si une monture est visible ou non et peut interagir avec. Un état de montage détermine si un membre d'un groupe de pairs peut recevoir l'événement. Selon la même documentation du noyau, il existe cinq états de montage :
- partagé - Une monture qui appartient à un groupe de pairs. Toute modification apportée se propagera à tous les membres du groupe de pairs.
- esclave - Propagation unidirectionnelle. Le point de montage maître propagera les événements à un esclave, mais le maître ne verra aucune des actions entreprises par l'esclave.
- partagé et esclave - Indique que le point de montage a un maître, mais qu'il a également son propre groupe de pairs. Le maître ne sera pas informé des modifications apportées à un point de montage, mais tous les membres du groupe de pairs en aval le seront.
- privé - Ne reçoit ni ne transmet aucun événement de propagation.
- non contraignant - Ne reçoit ni ne transmet aucun événement de propagation et ne peut pas être lié monté.
Il est important de noter que l'état du point de montage est par point de montage . Cela signifie que si vous avez / et /boot , par exemple, vous devrez appliquer séparément l'état souhaité à chaque point de montage.
Si vous vous posez des questions sur les conteneurs, la plupart des moteurs de conteneurs utilisent des états de montage privés lors du montage d'un volume à l'intérieur d'un conteneur. Ne vous en faites pas trop pour l'instant. Je veux juste donner un peu de contexte. Si vous souhaitez essayer des scénarios de montage spécifiques, consultez les pages de manuel car les exemples sont assez bons.
Création de notre espace de noms de montage
Si vous utilisez un langage de programmation tel que Go ou C, vous pouvez utiliser les appels bruts du noyau système pour créer l'environnement approprié pour vos nouveaux espaces de noms. Cependant, étant donné que l'intention derrière cela est de vous aider à comprendre comment interagir avec un conteneur qui existe déjà, vous devrez faire quelques trucs bash pour obtenir votre nouvel espace de noms de montage dans l'état souhaité.
Tout d'abord, créez le nouvel espace de noms de montage en tant qu'utilisateur normal :
unshare -Urm
Une fois que vous êtes dans l'espace de noms, regardez le findmnt du périphérique mappeur, qui contient le système de fichiers racine (par souci de brièveté, j'ai supprimé la plupart des options de montage de la sortie) :
findmnt |grep mapper
/ /dev/mapper/cs-root xfs rw,relatime,[...] Il n'y a qu'un seul point de montage qui a le mappeur de périphérique racine. Ceci est important car l'une des choses que vous devez faire est de lier le périphérique de mappage dans le répertoire Alpine :
export CONTAINER_ROOT_FOLDER=/container_practice
mount --bind ${CONTAINER_ROOT_FOLDER}/fakeroot ${CONTAINER_ROOT_FOLDER}/fakeroot
cd ${CONTAINER_ROOT_FOLDER}/fakeroot
C'est parce que vous utilisez un utilitaire appelé pivot_root pour effectuer un chroot -comme une action. pivot_root prend deux arguments :new_root et old_root (parfois appelé put_old ). pivot_root déplace le système de fichiers racine du processus en cours vers le répertoire put_old et fait new_root le nouveau système de fichiers racine.
IMPORTANT :Une note à propos de chroot . chroot est souvent considéré comme ayant des avantages de sécurité supplémentaires. Dans une certaine mesure, c'est vrai, car il faut une expertise plus importante pour s'en libérer. Un chroot soigneusement construit peut être très sécurisé. Cependant, chroot ne modifie ni ne restreint les capacités de Linux que j'ai abordées dans l'article précédent sur l'espace de noms. Il ne limite pas non plus les appels système au noyau. Cela signifie qu'un agresseur suffisamment qualifié pourrait potentiellement échapper à un chroot cela n'a pas été bien pensé. Les espaces de noms de montage et d'utilisateur aident à résoudre ce problème.
Si vous utilisez pivot_root sans le montage lié, la commande répond par :
pivot_root: failed to change root from `.' to `old_root/': Invalid argument
Pour basculer vers le système de fichiers racine Alpine, commencez par créer un répertoire pour old_root puis pivotez dans le système de fichiers racine prévu (Alpine). Étant donné que le système de fichiers racine Alpine Linux n'a pas de liens symboliques pour /bin et /sbin , vous devrez les ajouter à votre chemin et enfin, démonter le old_root :
mkdir old_root
pivot_root . old_root
PATH=/bin:/sbin:$PATH
umount -l /old_root
Vous avez maintenant un bel environnement où l'utilisateur et monter Les espaces de noms fonctionnent ensemble pour fournir une couche d'isolation de l'hôte. Vous n'avez plus accès aux fichiers binaires sur l'hôte. Essayez d'émettre le findmnt commande que vous utilisiez auparavant :
root@new-mnt$ findmnt
-bash: findmnt: command not found Vous pouvez également consulter le système de fichiers racine ou essayer de voir ce qui est monté :
root@new-mnt$ ls -l /
total 12
drwxr-xr-x 2 root root 4096 Jan 28 21:51 bin
drwxr-xr-x 2 root root 18 Feb 17 22:53 dev
drwxr-xr-x 15 root root 4096 Jan 28 21:51 etc
drwxr-xr-x 2 root root 6 Jan 28 21:51 home
drwxr-xr-x 7 root root 247 Jan 28 21:51 lib
drwxr-xr-x 5 root root 44 Jan 28 21:51 media
drwxr-xr-x 2 root root 6 Jan 28 21:51 mnt
drwxrwxr-x 2 root root 6 Feb 17 23:09 old_root
drwxr-xr-x 2 root root 6 Jan 28 21:51 opt
drwxr-xr-x 2 root root 6 Jan 28 21:51 proc
drwxr-xr-x 2 root root 6 Feb 17 22:53 put_old
drwx------ 2 root root 27 Feb 17 22:53 root
drwxr-xr-x 2 root root 6 Jan 28 21:51 run
drwxr-xr-x 2 root root 4096 Jan 28 21:51 sbin
drwxr-xr-x 2 root root 6 Jan 28 21:51 srv
drwxr-xr-x 2 root root 6 Jan 28 21:51 sys
drwxrwxrwt 2 root root 6 Feb 19 16:38 tmp
drwxr-xr-x 7 root root 66 Jan 28 21:51 usr
drwxr-xr-x 12 root root 137 Jan 28 21:51 var
root@new-mnt$ mount
mount: no /proc/mounts
Fait intéressant, il n'y a pas de proc système de fichiers monté par défaut. Essayez de le monter :
root@new-mnt$ mount -t proc proc /proc
mount: permission denied (are you root?)
root@new-mnt$ whoami
root
Parce que proc est un type spécial de montage lié à l'espace de noms PID, vous ne pouvez pas le monter même si vous êtes dans votre propre espace de noms de montage. Cela revient à l'héritage de capacité dont j'ai parlé plus tôt. Je reprendrai cette discussion dans le prochain article lorsque je couvrirai l'espace de noms PID. Cependant, pour rappel sur l'héritage, regardez le schéma ci-dessous :
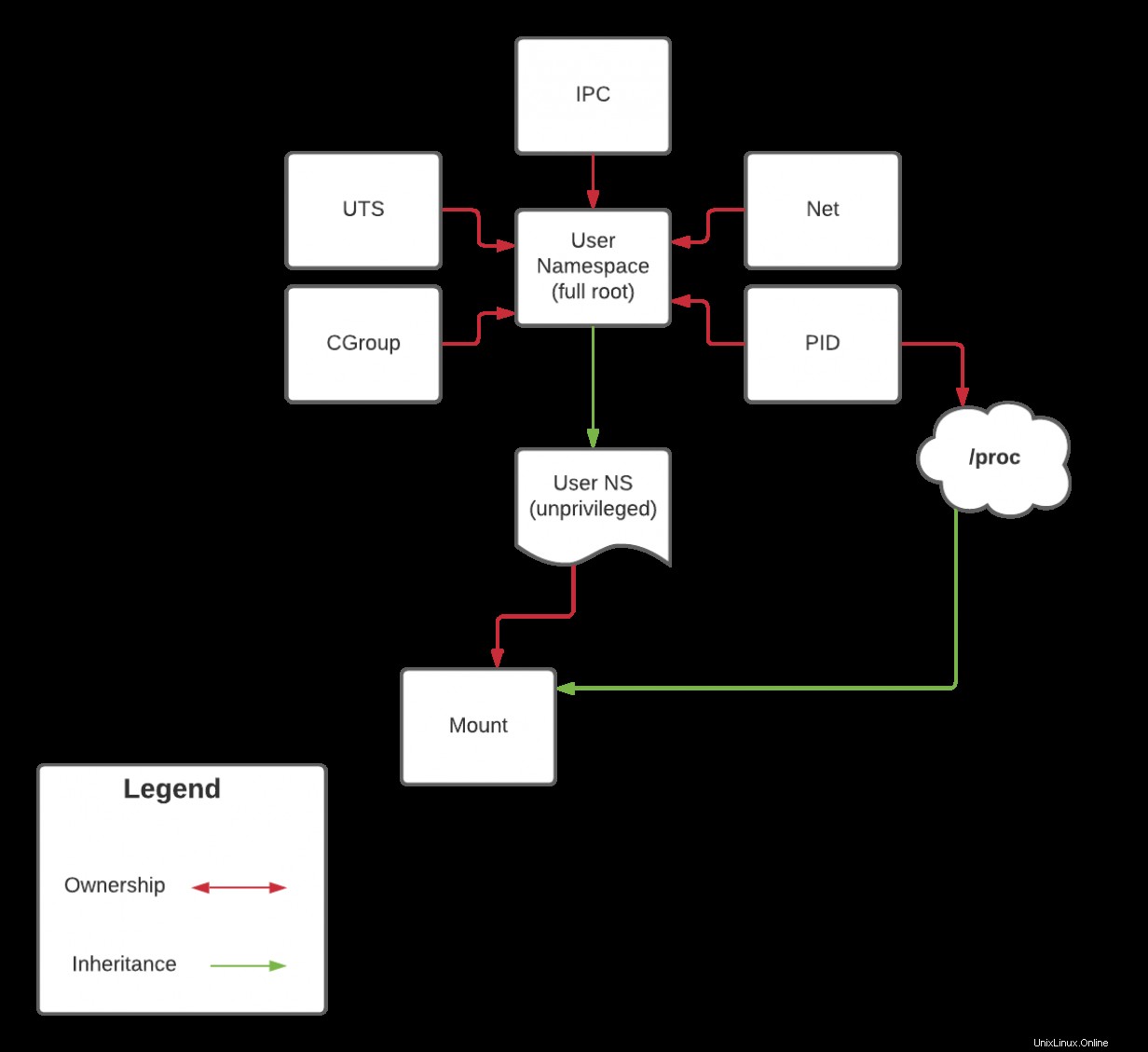
Dans le prochain article, je ressasserai ce diagramme, mais si vous avez suivi depuis le début, vous devriez pouvoir faire quelques inférences avant.
[ Manuel du propriétaire de l'API :7 bonnes pratiques pour des programmes d'API efficaces ]
Conclusion
Dans cet article, j'ai couvert une théorie plus approfondie autour de l'espace de noms de montage. J'ai discuté des groupes de pairs et de leur relation avec les états de montage appliqués à chaque point de montage sur un système. Pour la partie pratique, vous avez téléchargé un système de fichiers Alpine Linux minimal, puis expliqué comment utiliser l'utilisateur et monter les espaces de noms pour créer un environnement qui ressemble beaucoup à chroot sauf potentiellement plus sécurisé.
Pour l'instant, testez le montage des systèmes de fichiers à l'intérieur et à l'extérieur de votre nouvel espace de noms. Essayez de créer de nouveaux points de montage qui utilisent le partagé , privé , et esclave états de montage. Dans le prochain article, j'utiliserai l'espace de noms PID pour continuer à créer le conteneur primitif afin d'accéder au proc isolation du système de fichiers et des processus.