Vous avez donc entendu parler de cette chose appelée cgroups, et vous souhaitez en savoir plus. Peut-être en avez-vous entendu parler en écoutant une conférence sur la conteneurisation. Peut-être cherchiez-vous à régler les performances de Linux, ou peut-être avez-vous traversé votre système de fichiers un jour et découvert /sys/fs/cgroups . Dans tous les cas, vous souhaitez en savoir plus sur cette fonctionnalité intégrée au noyau depuis un certain temps. Alors asseyez-vous, prenez du pop-corn et préparez-vous à (espérons-le) apprendre quelque chose que vous ne saviez peut-être pas auparavant.
Que sont les groupes de contrôle ?
Le dictionnaire Webster définit les cgroups comme... Je plaisante. J'ai toujours détesté écouter des conférences qui commençaient par des définitions de dictionnaires ennuyeuses. Au lieu de cela, je vais essayer de distiller la définition technique des cgroups en quelque chose de facile à comprendre.
Les Cgroups sont un vaste sujet. J'ai décomposé cette discussion en une série de quatre parties. La première partie, cet article, couvre les concepts fondamentaux des cgroups. La deuxième partie examine CPUShare plus en profondeur. La troisième partie, intitulée "Faire des cgroups à la dure", examine les tâches administratives des cgroups. Enfin, la quatrième partie couvre les cgroups gérés par systemd.
Comme vous le savez peut-être ou non, le noyau Linux est responsable de l'interaction fiable de tout le matériel sur un système. Cela signifie qu'en plus des bits de code (pilotes) qui permettent au système d'exploitation (OS) de comprendre le matériel, il définit également des limites sur le nombre de ressources qu'un programme particulier peut exiger du système. Ceci est plus facile à comprendre lorsque l'on parle de la quantité de mémoire (RAM) qu'un système doit répartir entre toutes les applications que votre ordinateur peut exécuter. Dans sa forme la plus élémentaire, un système Linux est autorisé à exécuter la plupart des applications sans restriction. Cela peut être très utile pour l'informatique générale si toutes les applications fonctionnent bien ensemble. Mais que se passe-t-il s'il y a un bogue dans un programme et qu'il commence à consommer toute la mémoire disponible ? Le noyau dispose d'une fonction appelée Out Of Memory (OOM) Killer. Son travail consiste à arrêter les applications afin de libérer suffisamment de RAM pour que le système d'exploitation puisse continuer à fonctionner sans planter.
C'est super, dites-vous, mais qu'est-ce que cela a à voir avec les cgroups ? Eh bien, le processus OOM agit comme une dernière ligne de défense avant que votre système ne s'effondre autour de vous. C'est utile jusqu'à un certain point, mais puisque le noyau peut contrôler quels processus doivent survivre au MOO, il peut également déterminer quelles applications ne peuvent pas consommer trop de RAM en premier lieu.
Les groupes de contrôle sont donc une fonctionnalité intégrée au noyau qui permet à l'administrateur de définir des limites d'utilisation des ressources sur n'importe quel processus du système. En général, les cgroups contrôlent :
- Le nombre de parts de CPU par processus.
- Les limites de mémoire par processus.
- Bloquer les E/S de l'appareil par processus.
- Quels paquets réseau sont identifiés comme étant du même type afin qu'une autre application puisse appliquer les règles de trafic réseau.
Il y a plus de facettes que celles-ci, mais ce sont les principales catégories qui intéressent la plupart des administrateurs.
Les modestes débuts des Cgroups
Les groupes de contrôle (cgroups) sont un mécanisme du noyau Linux pour un contrôle précis des ressources. Proposés à l'origine par les ingénieurs de Google en 2006, les cgroups ont finalement été fusionnés dans le noyau Linux vers 2007. Bien qu'il existe actuellement deux versions de cgroups, la plupart des distributions et des mécanismes utilisent la version 1, telle qu'elle est dans le noyau depuis 2.6.24. Comme avec la plupart des choses ajoutées au noyau principal, il n'y avait pas un taux d'adoption énorme au début. La version 2 poursuit cette tendance, puisqu'elle existe depuis près d'une demi-décennie, mais qu'elle n'est toujours pas largement déployée.
Un problème qui afflige l'adoption des cgroups est le manque de connaissance de son existence et de son rôle dans le système Linux moderne. Une faible sensibilisation et adoption signifie souvent que l'interaction avec une interface de noyau est maladroite, alambiquée ou tout simplement un processus manuel. Tel était le cas avec les cgroups initialement. Bien sûr, il n'est pas si difficile de créer des cgroups uniques. Par exemple, si vous vouliez simuler les premiers jours avant que l'outil autour des cgroups ne soit développé, vous pourriez créer un tas de répertoires, monter le cgroup système de fichiers et commencez à tout configurer à la main. Mais avant d'aborder tout cela, parlons un peu de pourquoi Les cgroups sont essentiels dans l'écosystème Linux d'aujourd'hui.
Pourquoi les groupes de contrôle sont importants
Les Cgroups ont quatre fonctionnalités principales étroitement liées les unes aux autres qui les rendent très importantes dans un système moderne, en particulier si vous exécutez une charge de travail conteneurisée.
1. Limitation des ressources
Comme évoqué précédemment, les cgroups permettent à un administrateur de s'assurer que les programmes exécutés sur le système restent dans certaines limites acceptables pour le processeur, la RAM, les E/S de périphérique de bloc et les groupes de périphériques.
REMARQUE :Les groupes d'appareils CGroup peuvent être un élément clé de la stratégie de sécurité globale de votre système. Les groupes d'appareils incluent le contrôle des autorisations de lecture, d'écriture et de mknod opérations. Les opérations de lecture/écriture sont assez explicites, alors prenons un moment pour regarder le mknod fonctionnalité dans un système Linux. mknod a été initialement conçu pour remplir toutes les choses qui apparaissent dans /dev/ . Ce sont des choses comme les disques durs, les interfaces USB pour des appareils tels que les microcontrôleurs Arduino, ESP8266 ou d'autres appareils qui pourraient exister sur un système. La plupart des systèmes Linux modernes utilisent udev pour remplir automatiquement ce système de fichiers virtuel avec les éléments détectés par le noyau. mknod permet également à plusieurs programmes de communiquer entre eux en créant un tube nommé. Ce concept sort du cadre de cette explication, mais il suffit de comprendre que cela facilite la transmission d'informations d'un programme à un autre. Quoi qu'il en soit, le mknod dans un environnement contrôlé est quelque chose qu'un administrateur devrait examiner de près pour restreindre.
2. Priorisation
La hiérarchisation est légèrement différente de la limitation des ressources car vous ne limitez pas nécessairement les processus. Au lieu de cela, vous dites simplement que, quel que soit le nombre de ressources disponibles, traitez X aura toujours plus de temps sur le système que le processus Y .
3. Comptabilité
Bien que la comptabilité soit désactivée par défaut pour la plupart des versions d'entreprise de Linux en raison de l'utilisation de ressources supplémentaires, il peut être très utile d'activer l'utilisation des ressources pour une arborescence particulière (plus à ce sujet plus tard). Vous pouvez ainsi voir quels processus à l'intérieur de quel groupe de contrôle consomment quels types ou ressources.
4. Contrôle de processus
Il existe une fonctionnalité dans les cgroups appelée freezer . Bien qu'une compréhension approfondie de cette fonctionnalité sorte du cadre de cet article, vous pouvez considérer le congélateur comme la possibilité de prendre un instantané d'un processus particulier et de le déplacer. Consultez la documentation du noyau pour une compréhension plus approfondie.
Bon, alors qu'est-ce que tout cela signifie? Eh bien, du point de vue d'un administrateur système, cela signifie plusieurs choses.
Tout d'abord, même sans plonger dans la technologie des conteneurs, cela signifie que vous pouvez obtenir une plus grande densité sur un seul serveur en gérant soigneusement le type de charge de travail, les applications et les ressources dont elles ont besoin.
Deuxièmement, cela améliore considérablement votre posture de sécurité. Alors qu'une installation typique de Linux utilise des cgroups par défaut, elle n'impose aucune restriction sur les processus. Vous pouvez imposer des restrictions par défaut si vous le souhaitez. Vous pouvez également restreindre l'accès à des appareils spécifiques pour des utilisateurs, des groupes ou des processus spécifiques, ce qui aide davantage à verrouiller un système.
Enfin, vous pouvez effectuer une quantité importante de réglage des performances via les cgroups. Cela, combiné à tuned, signifie que vous pouvez créer un environnement spécifiquement adapté à vos charges de travail individuelles. À grande échelle ou dans un environnement sensible à la latence, ces ajustements peuvent faire la différence entre respecter ou manquer vos accords de niveau de service (SLA).
Comment fonctionnent les groupes de contrôle ?
Pour les besoins de cette discussion, nous parlons de cgroups V1 . Bien que la version 2 soit disponible dans Red Hat Enterprise Linux 8 (RHEL 8), elle est désactivée par défaut. La plupart des technologies de conteneurs telles que Kubernetes, OpenShift, Docker, etc. reposent toujours sur la version 1 de cgroups.
Nous avons déjà expliqué que les cgroups sont un mécanisme de contrôle de certains sous-systèmes du noyau. Ces sous-systèmes, tels que les périphériques, le processeur, la RAM, l'accès au réseau, etc., sont appelés contrôleurs. dans la terminologie cgroup.
Chaque type de contrôleur (cpu , blkio , memory , etc.) est subdivisé en une structure arborescente. Chaque branche ou feuille a ses propres poids ou limites. Un groupe de contrôle est associé à plusieurs processus, ce qui rend l'utilisation des ressources granulaire et facile à ajuster.
REMARQUE :Chaque enfant hérite et est limité par les limites définies sur le cgroup parent.
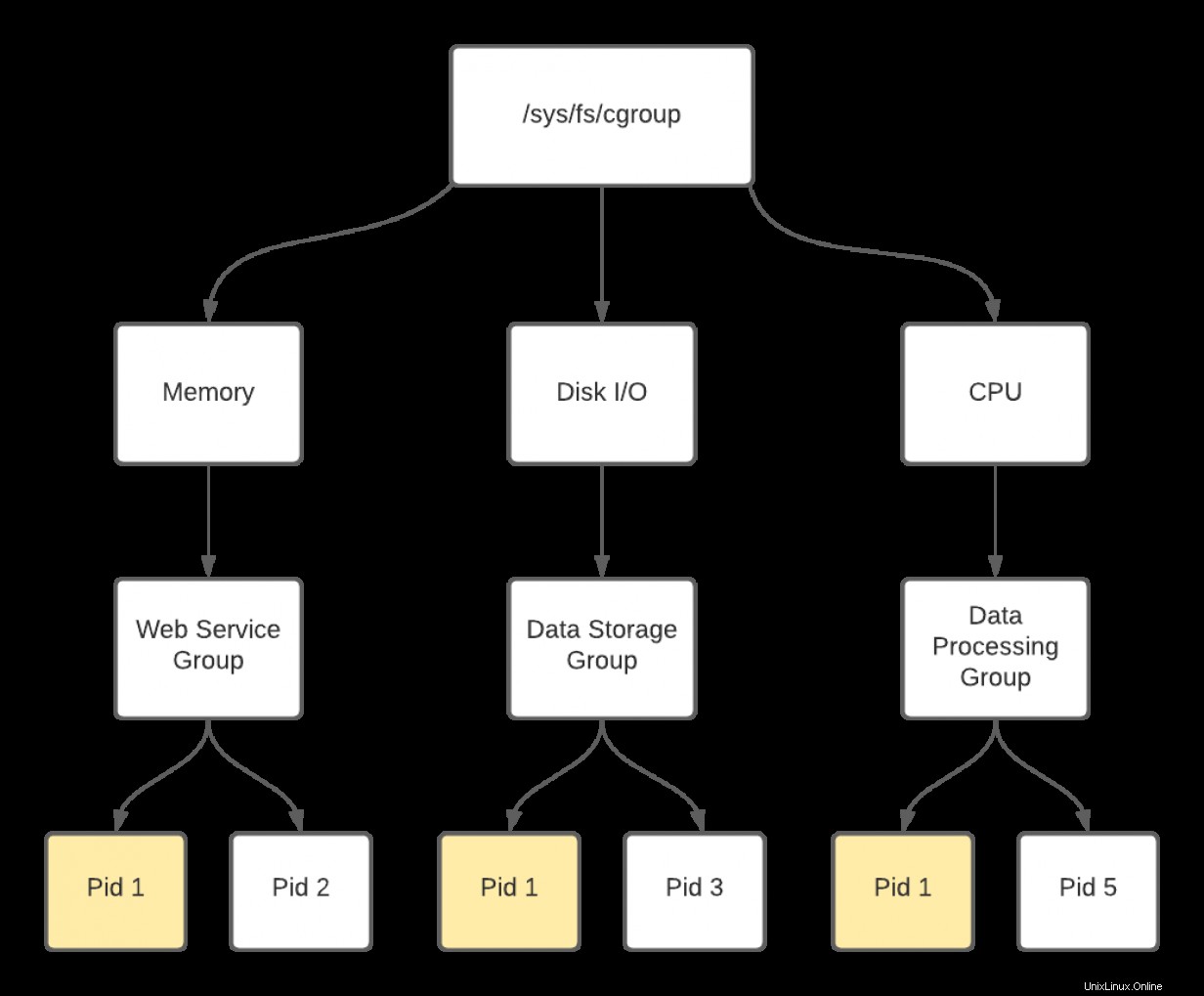
Dans le schéma ci-dessus, vous pouvez voir qu'il est possible d'avoir PID 1 en memory , disk i/o , et cpu groupes de contrôle. Les cgroups sont créés par type de ressource et n'ont aucune association entre eux. Cela signifie que vous pourriez avoir une database groupe associé à tous les contrôleurs, mais les groupes sont traités indépendamment. Comme les GID, ces groupes se voient attribuer une valeur numérique lors de la création et non un nom convivial. Sous le capot, le noyau utilise ces valeurs pour déterminer l'allocation des ressources. Pour y penser autrement, supposons que chaque nom de groupe de contrôle, une fois attaché à un contrôleur, est renommé avec le nom du contrôleur plus le nom de votre choix. Donc un groupe appelé database dans la memory le contrôleur peut en fait être considéré comme memory-database . Ainsi, il n'y a aucune relation avec une database groupe associé au contrôleur cpu car le nom convivial peut être considéré comme cpu-database .
REMARQUE :Il s'agit d'une simplification grossière et n'est PAS techniquement exacte si vous cherchez à vous impliquer dans le code de groupe de contrôle sous-jacent. L'explication ci-dessus est destinée à la clarté de la compréhension.
Récapitulez
Vous avez maintenant une idée de ce que sont les cgroups et de la manière dont ils peuvent vous aider à régler les performances et la sécurité. Vous avez également une meilleure compréhension de la façon dont les cgroups interagissent avec les contrôleurs.
Cet article n'est pas une ventilation de tous les types de contrôleurs qui existent dans les cgroups. Quelque chose à cette échelle prendrait un livre entier pour être expliqué correctement. Dans le prochain article, j'examine les CPUShares en raison de leur complexité relative et de l'importance qu'ils jouent dans la santé globale d'un système. Les autres contrôleurs fonctionnent de la même manière. Par conséquent, vous devriez être en mesure de tirer les leçons du contrôleur CPU et de les appliquer à la plupart des contrôleurs de groupe de contrôle restants.
N'oubliez pas que dans la troisième partie, nous examinerons les tâches administratives et dans la quatrième partie, nous conclurons sur la façon dont systemd interagit avec les cgroups.
[ Vous débutez avec les conteneurs ? Découvrez ce cours gratuit. Déploiement d'applications conteneurisées :présentation technique. ]